

Indexing Word 2007 (docx) files with Zend_Search_Lucene
Edit on GitHubYou may have noticed Microsoft released their Search Server 2008 a few weeks ago. Search Server delivers search capabilities to your organization quickly and easily. The PHP world currently does not have a full-featured solution like Search Server, but there's a building block which could be used to create something similar: Zend Framework's PHP port of Lucene. There is also a .NET port of Lucene available.
Lucene basically is an indexing and search technology, providing an easy-to-use API to create any type of application that has to do with indexing and searching. If you provide the right methods to extract data from any type of document, Lucene can index it. There are various indexer examples available for different file formats (PDF, HTML, RSS, ...), but none for Word 2007 (docx) files. Sounds like a challenge!
Source code
Want the full code? Download it here.
Prerequisites
Make sure you use PHP version 5.2, have php_zip and php_xml enabled, and have a working Zend Framework installation on your computer. Another useful thing is to have the Lucene manual pages aside along the way.
1. Creating an index
 Let's start with creating a Zend_Search_Lucene index. We will be needing the Zend Framework classes, so let's start with including them:
Let's start with creating a Zend_Search_Lucene index. We will be needing the Zend Framework classes, so let's start with including them:
[code:c#]
/** Zend_Search_Lucene */
require_once 'Zend/Search/Lucene.php';
[/code]
We will also be needing an index database. The following code snippets checks for an existing database first (in ./lucene_index/). If it exists, the snippets loads the index database, otherwise a new index database is created.
[code:c#]
// Index
$index = null;
// Verify if the index exists. If not, create it.
if (is_dir('./lucene_index/') == 1) {
$index = Zend_Search_Lucene::open('./lucene_index/');
} else {
$index = Zend_Search_Lucene::create('./lucene_index/');
}
[/code]
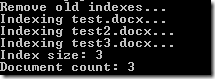
Now since the document root we are indexing might have different contents on every indexer run, let's first remove all documents from the existig index. Here's how:
[code:c#]
// Remove old indexed files
for ($i = 0; $i < $index->maxDoc(); $i++) {
$index->delete($i);
}
[/code]
We'll create an index entry for the file test.docx. We will be adding some fields to the index, like the url where the original document can be found, the text of the document (which will be tokenized, indexed, but not completely stored as the index might grow too big fast!).
[code:c#]
// File to index
$fileToIndex = './test.docx';
// Index file
echo 'Indexing ' . $fileToIndex . '...' . "\r\n";
// Create new indexed document
$luceneDocument = new Zend_Search_Lucene_Document();
// Store filename in index
$luceneDocument->addField(Zend_Search_Lucene_Field::Text('url', $fileToIndex));
// Store contents in index
$luceneDocument->addField(Zend_Search_Lucene_Field::UnStored('contents', DocXIndexer::readDocXContents($fileToIndex)));
// Store document properties
$documentProperties = DocXIndexer::readCoreProperties($fileToIndex);
foreach ($documentProperties as $key => $value) {
$luceneDocument->addField(Zend_Search_Lucene_Field::UnIndexed($key, $value));
}
// Store document in index
$index->addDocument($luceneDocument);
[/code]
After creating the index, there's one thing left: optimizing it. Zend_Search_Lucene offers a nice method to doing that in one line of code: $index->optimize(); Since shutdown of the index instance is done automatically, the $index->commit(); command is not necessary, but it's good to have it present so you know what happens at the end of the indexing process.
There, that's it! Our index (of one file...) is now ready! I must admit I did not explain all the magic... One piece of the magic is the DocXIndexer class whose method readDocXContents() is used to retrieve all text from a Word 2007 file. Here's how this method is built.
2. Retrieving the full text from a Word 2007 file
The readDocXContents() method mentioned earlier is the actual "magic" in this whole process. It basically reads in a Word 2007 (docx) file, loops trough all paragraphs and extracts all text runs from these paragraphs into one string.
A Word 2007 (docx) is a ZIP-file (container), which contains a lot of XML files. Some of these files describe a document and some of them describe the relationships between these files. Every XML file is validated against an XSD schema, which we'll define first:
[code:c#]
// Schemas
$relationshipSchema = 'http://schemas.openxmlformats.org/package/2006/relationships';
$officeDocumentSchema = 'http://schemas.openxmlformats.org/officeDocument/2006/relationships/officeDocument';
$wordprocessingMLSchema = 'http://schemas.openxmlformats.org/wordprocessingml/2006/main';
[/code]
The $relationshipSchema is the schema name that describes a relationship between the OpenXML package (the ZIP-file) and the containing XML file ("part"). The $officeDocumentSchema is the main document part describing it is a Microsoft Office document. The $wordprocessingMLSchema is the schema containing all Word-specific elements, such as paragrahps, runs, printer settings, ... But let's continue coding. I'll put the entire code snippet here and explain every part later:
[code:c#]
// Returnvalue
$returnValue = array();
// Documentholders
$relations = null;
// Open file
$package = new ZipArchive(); // Make sure php_zip is enabled!
$package->open($fileName);
// Read relations and search for officeDocument
$relations = simplexml_load_string($package->getFromName("_rels/.rels"));
foreach ($relations->Relationship as $rel) {
if ($rel["Type"] == $officeDocumentSchema) {
// Found office document! Now read in contents...
$contents = simplexml_load_string(
$package->getFromName(dirname($rel["Target"]) . "/" . basename($rel["Target"]))
);
$contents->registerXPathNamespace("w", $wordprocessingMLSchema);
$paragraphs = $contents->xpath('//w:body/w:p');
foreach($paragraphs as $paragraph) {
$runs = $paragraph->xpath('//w:r/w:t');
foreach ($runs as $run) {
$returnValue[] = (string)$run;
}
}
break;
}
}
// Close file
$package->close();
// Return
return implode(' ', $returnValue);
[/code]
The first thing that is loaded, is the main ".rels" document, which contains a reference to all parts in the root of this OpenXML package. This file is parsed using SimpleXML into a local variable $relations. Each relationship has a type ($rel["Type"]), which we compare against the $officeDocumentSchema schema name. When that schema name is found, we dig deeper into the document, parsing it into $contents. Next on our todo list: register the $wordprocessingMLSchema for running an XPath query on the document.
[code:c#]
$contents->registerXPathNamespace("w", $wordprocessingMLSchema);
[/code]
We can now easily run an XPath query "//w:body/w:p", which retrieves all w:p childs (paragraphs) of the document's body:
[code:c#]
$paragraphs = $contents->xpath('//w:body/w:p');
[/code]
The rest is quite easy. In each paragraph, we run a new XPath query "//w:r/w:t", which delivers all text nodes withing the paragraph. Each of these text nodes is then added to the $returnValue, which will represent all text content in the main document part upon completion.
[code:c#]
foreach($paragraphs as $paragraph) {
$runs = $paragraph->xpath('//w:r/w:t');
foreach ($runs as $run) {
$returnValue[] = (string)$run;
}
}
[/code]
3. Searching the index
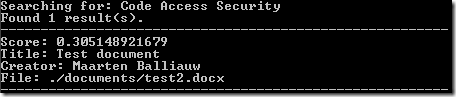 Searching the index starts the same way as creating the index: you first have to load the database. After loading the index database, you can easily run a query on it. Let's search for the keywords "Code Access Security":
Searching the index starts the same way as creating the index: you first have to load the database. After loading the index database, you can easily run a query on it. Let's search for the keywords "Code Access Security":
[code:c#]
// Search query
$searchFor = 'Code Access Security';
// Search in index
echo sprintf('Searching for: %s', $searchFor) . "\r\n";
$hits = $index->find( $searchFor );
echo sprintf('Found %s result(s).', count($hits)) . "\r\n";
echo '--------------------------------------------------------' . "\r\n";
foreach ($hits as $hit) {
echo sprintf('Score: %s', $hit->score) . "\r\n";
echo sprintf('Title: %s', $hit->title) . "\r\n";
echo sprintf('Creator: %s', $hit->creator) . "\r\n";
echo sprintf('File: %s', $hit->url) . "\r\n";
echo '--------------------------------------------------------' . "\r\n";
}
[/code]
There you go! That's all there is to it. Want the full code? Download it here: LuceneIndexingDOCX.zip (96.03 kb)
This is an imported post. It was imported from my old blog using an automated tool and may contain formatting errors and/or broken images.
0 responses